
3D Aware Region Prompted Vision Language Model
Region-level spatial reasoning for both single-view and multi-view inputs.
ICLR 2026
Region-level spatial reasoning for both single-view and multi-view inputs.
ICLR 2026A key idea of SR-3D is the introduction of a canonical positional representation shared across single-view and multi-view inputs. This unified representation enables large-scale single-view pretraining and supports the transfer of learned spatial priors to multi-view settings.
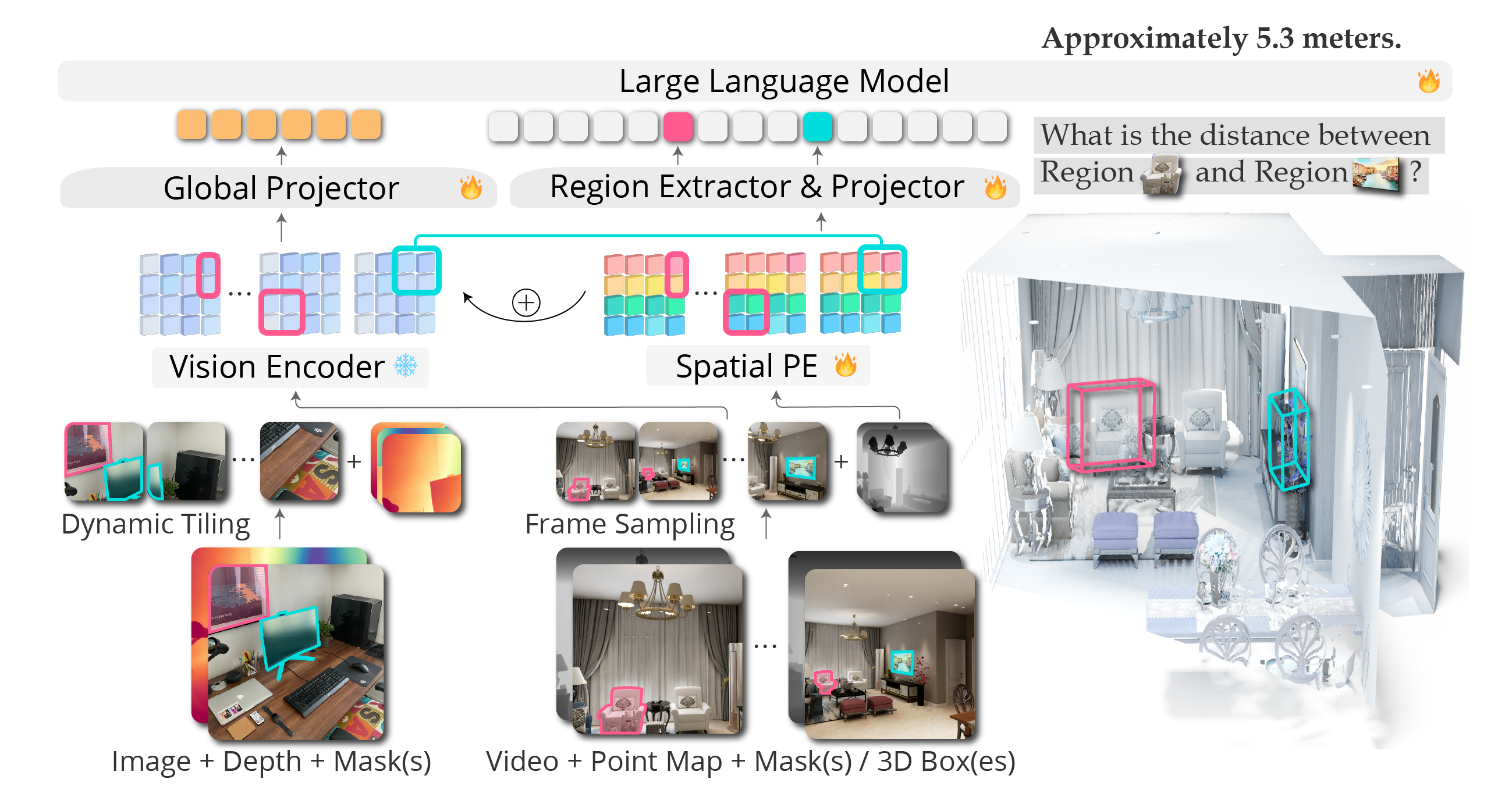
SR-3D consistently improves over the base model (NVILA-Lite-8B / SpatialRGPT-8B) across both 2D spatial and region-level benchmarks.


@inproceedings{cheng2026sr3d,
title={3D Aware Region Prompted Vision Language Model},
author={An-Chieh Cheng and Yang Fu and Yukang Chen and Zhijian Liu and Xiaolong Li and Subhashree Radhakrishnan and Song Han and Yao Lu and Jan Kautz and Pavlo Molchanov and Hongxu Yin and Xiaolong Wang and Sifei Liu},
booktitle={International Conference on Learning Representations},
year={2026},
}