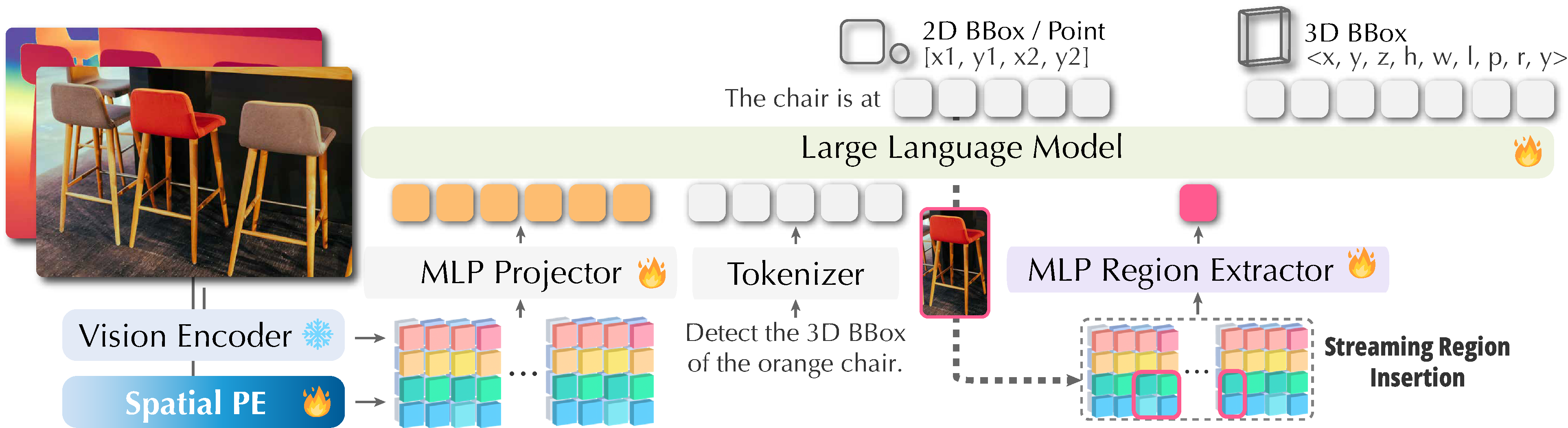
Grounded 3D-Aware
Spatial Vision-Language Modeling



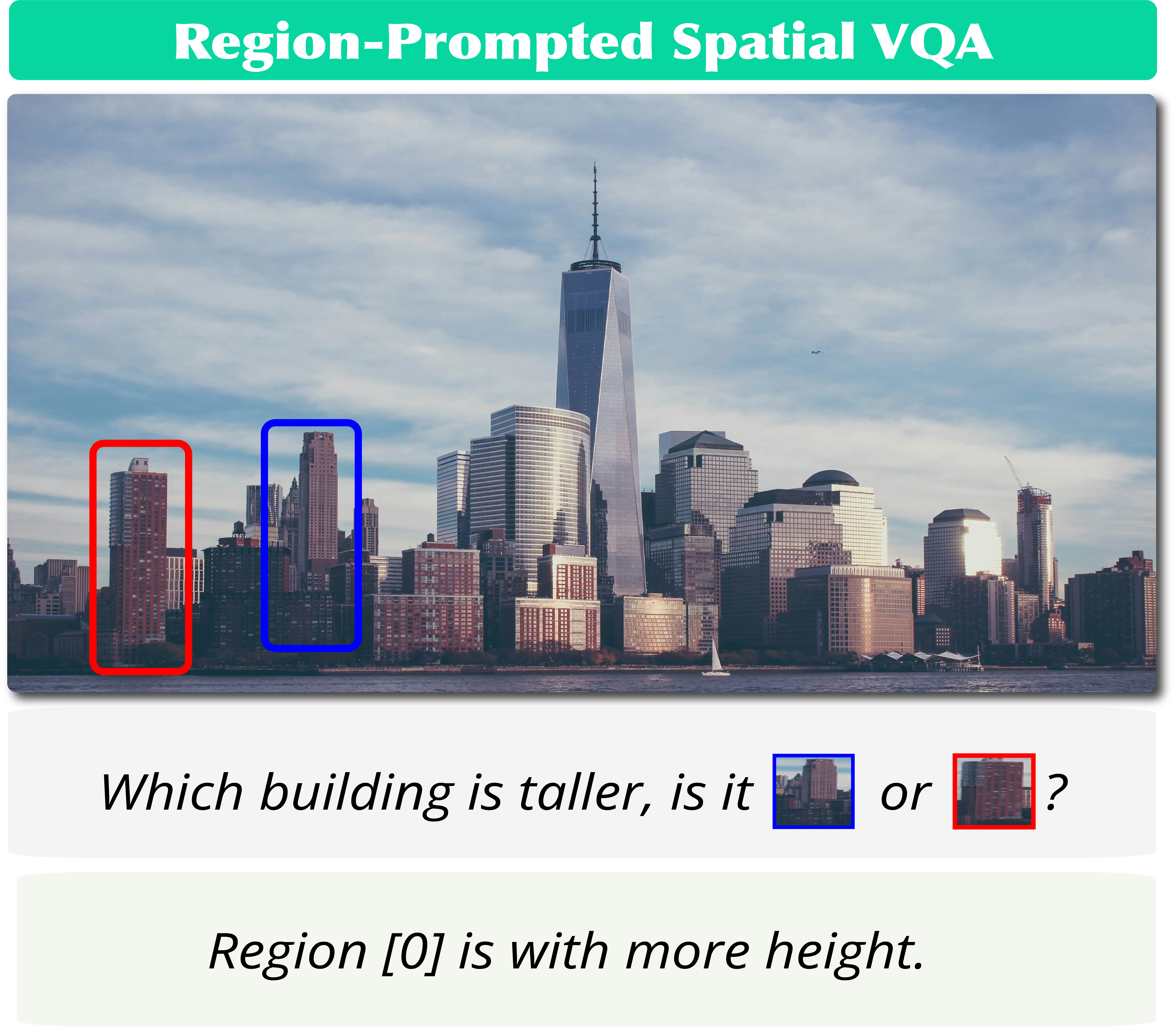




Detect then Lift vs Direct 3D Prediction
Grounding the target in 2D before predicting its 3D bounding box leads to clear performance gains, as shown in the table below. This two-step design encourages the model to first learn object-specific visual features and leverage abundant 2D supervision, which helps build stronger spatial priors and improves downstream 3D detection. We also compare against Qwen3-VL, a direct 3D prediction approach, and observe that it more easily misses the target.

Does spatial pretraining help 3D detection?
Yes. Spatial pretraining noticeably improves performance, especially in outdoor domains. Due to strong dataset imbalance in Omni3D, where outdoor samples are much fewer than indoor ones, models trained from scratch struggle to generalize. Spatial pretraining injects generic 2D spatial and grounding knowledge, allowing the model to transfer stronger spatial priors to 3D detection. As shown in the results, leveraging 2D supervision is particularly effective when 3D training data is limited or unevenly distributed.
Scaling Effect of 3D Point-Map Data
Pointmap reconstruction serves as an effective auxiliary task for 3D detection by improving the alignment between region-level visual features and their underlying 3D geometry. We show that increasing pointmap supervision leads to consistent performance gains on SUN-RGBD, suggesting that dense geometric reconstruction provides strong structural priors that enhance downstream 3D box prediction.
@inproceedings{gr3d,
title={Grounded 3D-Aware Spatial Vision-Language Modeling},
author={Cheng, An-Chieh and Fu, Yang and Ji, Yatai and Zhu, Ligeng and Zhan, Guanqi and Zhang, Zhuoyang and Yang, Zhaojing and Han, Song and Lu, Yao and Molchanov, Pavlo and Murali, Vidya Nariyambut and Kautz, Jan and Wang, Xiaolong and Yin, Hongxu and Liu, Sifei},
booktitle={Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition},
year={2026}
}