SpatialRGPT use relative depth maps alongside RGB images to enhance geometric reasoning. However, incorporating depth information is challenging because VLM visual encoders are typically only trained on text and 2D images. Simply combining RGB and depth features can harm performance. To address this, we introduce an add-on module that processes depth maps using the same image encoder and a depth-to-language connector. The weights of this connector, initialized from the RGB connector and trained on spatial-related QAs, enable the 2D encoder to flexibly utilize depth information without requiring extensive training data.
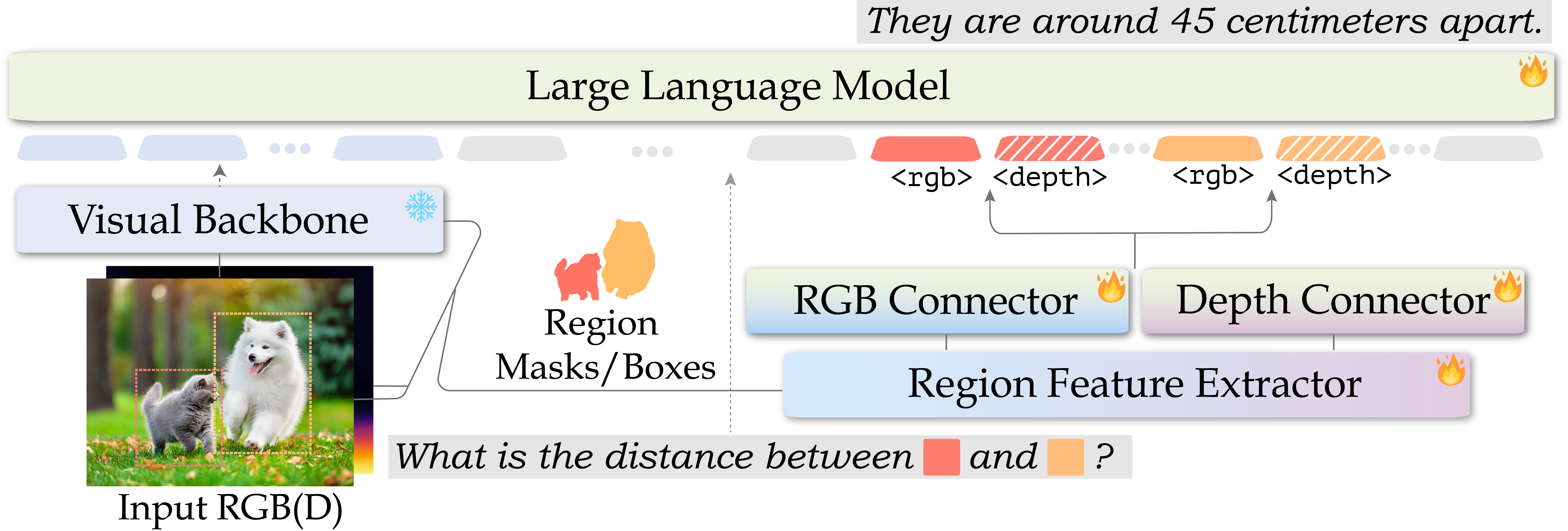
Having an effective training dataset is crucial. Our data pipeline generates 3D region-aware annotations from 2D images at scale by constructing a 3D scene graph for each image. This process involves three components: (i) open-vocabulary detection and segmentation (ii) metric depth estimation, and (iii) camera calibration. The scene graphs are then transformed into region-aware spatial QAs using both template-based and LLM-based approaches.
Our pipeline is completely automated and only needs RGB images. This enables us to utilize any available open-source data. We curate our dataset using OpenImages, resulting in 8.7M spatial concepts grounded in 5M unique regions from 1M images. Our results show that combining template-based QAs and LLM-based reasoning QAs helps develop a model capable of handling more complex spatial reasoning questions.

Currently, no visual-language benchmarks focus on VLMs’ understanding of 3D spatial concepts like metric distance or size differences between objects. To fill this gap, we developed SpatialRGPT-Bench, a spatial reasoning VQA benchmark using data from urban (nuScenes, KITTI), indoor (SUNRGBD, ARKitScenes), and simulated (Hypersim) environments. We use preprocessed ground-truth 3D cuboids from Omni3D, positioned within a unified 3D camera coordinate system and categorized by object classes.
| Method | Below/ Above |
Left/ Right |
Big/ Small |
Tall/ Short |
Wide/ Thin |
Behind/ Front |
Avg. |
|---|---|---|---|---|---|---|---|
| GPT-4 | 64.1 | 42.8 | 42.8 | 61.6 | 61.6 | 49.0 | 57.8 |
| GPT-4V | 63.3 | 46.6 | 64.1 | 60.7 | 68.2 | 45.4 | 58.1 |
| LLaVA-v1.6-34B | 44.1 | 45.7 | 36.7 | 53.5 | 37.5 | 45.4 | 43.9 |
| GPT-4V+SoM | 75.0 | 55.2 | 42.4 | 54.4 | 49.0 | 47.2 | 54.3 |
| LLaVA-v1.6-34B+SoM | 44.1 | 40.0 | 33.9 | 47.3 | 41.3 | 46.3 | 42.3 |
| Kosmos-2 | 28.3 | 15.2 | 4.71 | 26.7 | 12.5 | 12.7 | 17.0 |
| RegionVILA | 30.8 | 47.6 | 35.8 | 44.6 | 35.5 | 49.0 | 40.4 |
| SpatialRGPT | 99.1 | 99.0 | 79.2 | 89.2 | 83.6 | 87.2 | 89.8 |
| SpatialRGPT-Depth | 99.1 | 99.0 | 80.1 | 91.9 | 87.5 | 91.8 | 91.7 |
| Method | Direct Distance |
Horizontal Distance |
Vertical Distance |
Width | Height | Direction | ||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| GPT-4 | 21.6 | 1.29 | 11.5 | 2.08 | 33.0 | 0.65 | 52.3 | 0.52 | 48.1 | 1.40 | 34.6 | 83.7° |
| GPT-4V | 29.7 | 0.92 | 25.4 | 2.75 | 33.0 | 0.48 | 51.1 | 0.37 | 68.4 | 1.57 | 43.9 | 69.9° |
| LLaVA-v1.6-34B | 24.3 | 0.76 | 24.5 | 1.59 | 30.1 | 0.62 | 30.8 | 0.40 | 42.8 | 1.96 | 33.6 | 78.2° |
| GPT-4V+SoM | 25.7 | 1.02 | 22.1 | 2.36 | 33.9 | 0.64 | 45.8 | 0.70 | 62.4 | 1.08 | 54.2 | 55.5° |
| LLaVA-v1.6-34B+SoM | 12.8 | 1.15 | 20.4 | 1.79 | 11.3 | 0.95 | 9.02 | 0.91 | 7.52 | 3.11 | 12.8 | 33.3° |
| Kosmos-2 | 4.05 | >10 | 4.91 | >10 | 1.89 | 2.26 | 3.01 | 5.42 | 1.50 | 3.82 | 1.86 | 104° |
| RegionVILA | 22.3 | 1.30 | 24.6 | 3.26 | 17.9 | >10 | 36.8 | >10 | 49.6 | 1.61 | 35.5 | 79.8° |
| SpatialRGPT | 35.1 | 0.35 | 59.0 | 0.27 | 53.8 | 0.27 | 51.9 | 0.31 | 54.9 | 0.63 | 95.3 | 17.1° |
| SpatialRGPT-Depth | 41.2 | 0.33 | 65.6 | 0.25 | 51.9 | 0.27 | 49.6 | 0.31 | 57.9 | 0.61 | 95.3 | 15.4° |
SpatialRGPT can function as a complex spatial reasoner on its own. Unlike SpatialVLM, which uses GPT-4 for reasoning tasks and employs VLM only for basic spatial queries, SpatialRGPT directly integrates these two capabilities. In the sample below, we show that SpatialRGPT is capable of complex spatial reasoning, addressing gaps that current leading vision language models, such as GPT-4V, struggle with.
Recent research has shown that VLMs can annotate rewards for robotics tasks using natural language. However, challenges arise due to language ambiguity. SpatialRGPT addresses this by allowing direct specification of regions of interest. We conducted a real robot experiment where SpatialRGPT use bounding boxes for the fingertip and a green cube to annotate rewards based on the distance between these regions. The results indicated a decreasing distance as the fingertip approached the cube, with the depth variant performing slightly better than the RGB variant. This demonstrates SpatialRGPT’s effectiveness as a precise and efficient region-aware dense reward annotator.
@inproceedings{cheng2024spatialrgpt,
title={SpatialRGPT: Grounded Spatial Reasoning in Vision-Language Models},
author={Cheng, An-Chieh and Yin, Hongxu and Fu, Yang and Guo, Qiushan and Yang, Ruihan and Kautz, Jan and Wang, Xiaolong and Liu, Sifei},
booktitle={NeurIPS},
year={2024}
}
This website is adapted from Nerfies and GLaMM, licensed under a Creative Commons Attribution-ShareAlike 4.0 International License.